【超意訳】Googleの中の人が振り返る2017年のAI関連技術と深層学習(原題:2017 AI and Deep Learning in 2017 – A Year in Review)
標記にまつわる昨年のニュースを概観する記事がtwitter等で軽バズりしていたので、英語のリハビリがてら訳しました。良くわからんところはGoogle翻訳だったり、英文のままだったりしています。また、まだ日本語訳のない技術的な名称は可能な限り英語のままにしています。
Denny Britz (@dennybritz) | Twitterさんという、Googleのbrain team の人がWILDMLという自身のブログ?で書かれた記事のようです。
関係ないですが、Britzさんは現在、東京に在住のようです。当然ながら、技術的な話が多めですが、後半応用面のレビューと社会的な動きへの言及があります。
- AI and Deep Learning in 2017 – A Year in Review
- 強化学習が専門家の教師データなしで人間を打ち負かす
- 進化的アルゴリズムの復権
- WaveNet*1、CNN、及びAttention Mechanism*2
- ディープ・ラーニング・フレームワークの年
- 機械学習を学習する教材の充実
- アプリケーション:AI&医学
- アプリケーション:芸術とGANs
- アプリケーション:自動運転車
- アプリケーション:その他のイケてるプロジェクト
- オープンなデータセット
- ディープラーニングの再現性に関する話題
- カナダと中国の人工知能事情
- ハードウェアの戦争:Nvidia、Intel、Google、Tesla
- ハイプ(誇大宣伝)と失敗
- 注目を浴びたヘッドハンティングなんかの話題
- スタートアップの投資と買収
AI and Deep Learning in 2017 – A Year in Review
はい、どうも〜。今年もおしまいですね。全然ブログ更新できていなかったですが、今年WILDMLに寄せられた強化学習、進化的戦略、ベイジアンネットについて追っていきます。以下のトピックは、twitterの過去ログとWildMLニュースレターを振り返ってみた中で、繰り返し出てきたものです。当然のことながら、私はいくつかの重要なマイルストーンを逃していると思われますので、コメントの中で私に教えてください!
強化学習が専門家の教師データなしで人間を打ち負かす
今年の最大の成功事例は、おそらく世界最高の囲碁プレイヤーを破る強化学習エージェントAlphaGo(Nature paper)でした。 その探索空間の巨大さから、囲碁は数年前からMachine Learningテクニックの対象外と考えられていたのにも関わらずです。びっくりですね。
AlphaGoの最初のバージョンは、人間の専門家からのトレーニングデータを使用して自己学習し、セルフプレイ(self-play)とモンテカルロ木探索の適応によってさらに学習を深めます。それからすぐのちに、AlphaGo Zero(Mastering the game of Go without human knowledge | Nature)は、それをさらに進歩させ、[1705.08439] Thinking Fast and Slow with Deep Learning and Tree Searchの論文で以前に発表されたテクニックを使用して、人間の専門家からのトレーニングデータを使うことなく、囲碁を最初からプレイし学習できるようになりました。また、AlphaGoの最初のバージョンを手際よく打ち負かしました。
年末には、AlphaGo Zeroアルゴリズムがより一般化できることがわかりました。AlphaZeroはまったく同じ技術を使って囲碁とチェスと将棋を習得しました。興味深いことに、これらのプログラムは、最も経験豊かな囲碁プレイヤーでさえ驚いた動きをして、プレイヤーにAlphaGoから学び、それに応じて自分のプレイスタイルを調整するよう動機づけました。 この、機械学習相手の練習を簡単にするため、DeepMindは、AlphaGo Teach: Discover new and creative ways of playing Goというツールもリリースしました。
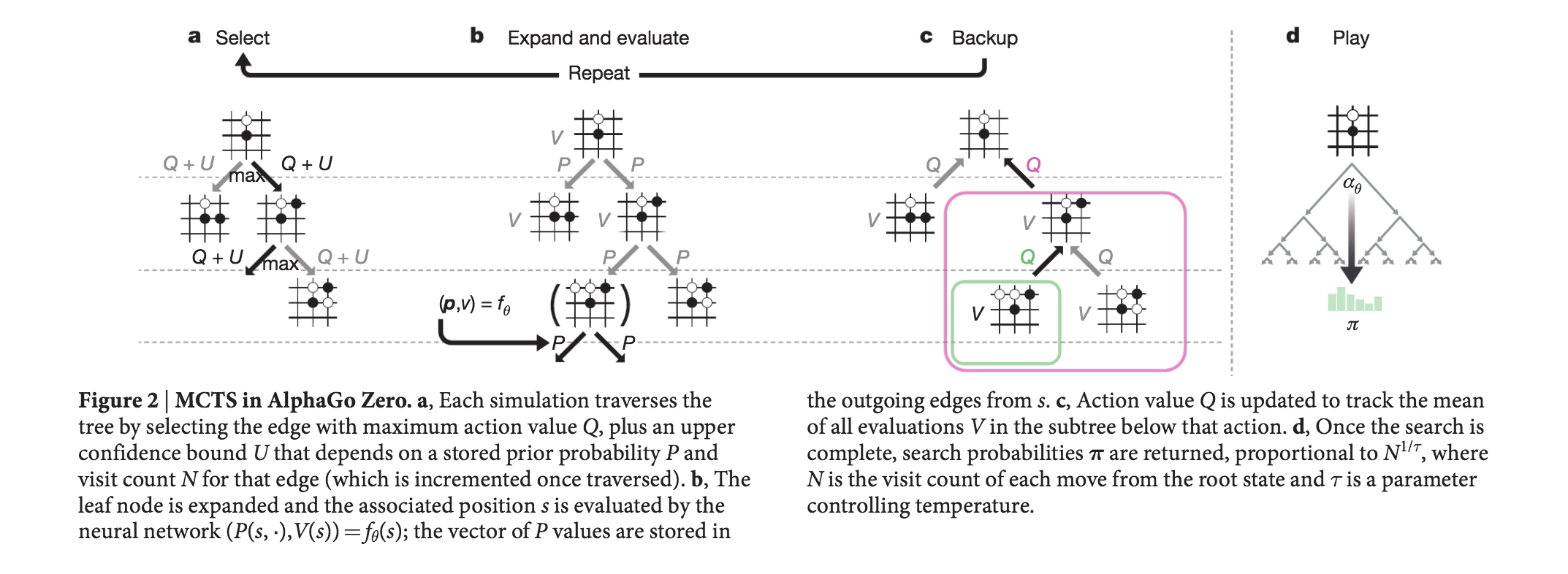
Alpha Go の躍進だけではなく、CMUの研究者によって開発されたシステムであるLibratus(Superhuman AI for heads-up no-limit poker: Libratus beats top professionals | Science)は、20日間のヘッズアップ(1 VS 1)のポーカー大会、ノーリミットテキサスホールデムトーナメントでトップのポーカープレーヤーを倒すことができました。 その少し前には、チャールズ大学、チェコ工科大学、アルバータ大学の研究者によって開発されたシステムであるDeepStackが、プロのポーカープレイヤーに勝利しました。
注意すべきは、これらのシステムは両方とも、2人のプレーヤーの間でプレーされるヘッズアップ(1 VS 1)ポーカーをプレイしており、これは複数プレーヤーのテーブルでプレーするよりもはるかに簡単な問題であったことです。複数プレイヤーとのゲームにおける機械学習の適用は、2018年にさらなる進展が見込まれる可能性が高いことでしょう。
強化学習の次のフロンティアは、ポーカーを含む、より複雑な複数プレーヤー同士のゲームのようです。 DeepMindは積極的に研究環境をリリースし、Starcraft 2を研究しています。OpenAIは近い将来、完全な5v5ゲームでの競争を目指して、1v1 Dota 2での初期成功を収めました。
進化的アルゴリズムの復権
教師あり学習の場合、バックプロパゲーションアルゴリズムを使用したgradient-based のアプローチは非常にうまく機能しています。 そして、それは当面はすぐには変わることはないでしょう。 しかし、強化学習では、進化的戦略(Evolution Strategies, ES)が復活しているようです。 データは一般的にiid(独立して同一分布)ではないため、誤差信号はより疎であり、探索の必要があるため、勾配に依存しないアルゴリズムは非常にうまくいく可能性があります。 さらに、進化的アルゴリズムは数千の機械に直線的に拡大して、非常に高速の並列訓練を可能にします。 高価なGPUを必要とせず、安価なCPUを多数(通常は数百から数千)訓練することができます。
今年の初め、OpenAIの研究者は、進化的戦略がDeep Q-Learningなどの標準強化学習アルゴリズムに匹敵するパフォーマンスを達成できることを実証しました(Evolution Strategies as a Scalable Alternative to Reinforcement Learning)。今年末にかけて、Uberのチームはブログ投稿と5つの研究論文のセットを発表し(Welcoming the Era of Deep Neuroevolution | Uber Engineering Blog)、遺伝的アルゴリズムとNovelty searchの可能性をさらに実証しました。 非常に単純な遺伝的アルゴリズムを使用し、勾配情報はまったくなく、彼らのアルゴリズムは難しいAtari Gamesを学習します。Frostbite(ゲームエンジン)に、10,500点のスコアを出した遺伝的アルゴリズム原則のビデオがあります。 このゲームではDQN、AC3、ESのスコアが1,000未満でした。
おそらく、2018年には、進化戦略を発展させる方向性でもっと多くの仕事が見られるでしょう。
WaveNet*1、CNN、及びAttention Mechanism*2
GoogleのTacotron 2テキスト読み上げシステムは、非常に印象的なオーディオサンプル*3を生成し、Google Assistantにも導入された自律型モデルWaveNetに基づいており、過去1年間で大幅なスピードの向上を見せています(High-fidelity speech synthesis with WaveNet | DeepMind)。WaveNetは以前からGoogle翻訳に採用されており、その結果として、RNNのアーキテクチャのトレーニング時間が短縮されました。
機械学習の一分野では、トレーニングに時間がかかる高価なRNNアーキテクチャーからの移行が進む傾向にあるようです。 [1706.03762] Attention Is All You Needによれば、研究者はRNNとCNNを使うことなく、より洗練されたAttentionのメカニズムを使用して、わずかなトレーニングコストで最先端の結果を達成することができるとされています。
ディープ・ラーニング・フレームワークの年
2017年を1つの文で要約すれば、それはフレームワークの年ということになるでしょう。FacebookはPyTorchと大きな飛躍を遂げました。 自然言語処理の研究においては、(Tensorflowなどの静的グラフフレームワークで宣言することが難しい)動的で再帰的な構造に定期的に対処しなければならないため、PyTorchは、(Chainerが提供するものと同様の)動的なグラフ構造を用いることのできるフレームワークとして重宝されています。
一方、Tensorflowのチームは2017年にかなり動いていました。Tensorflow 1.0は、安定した下位互換性のあるAPIを2月にリリースしました。 現在、Tensorflowはバージョン1.4.1です。 主要なフレームワークに加えて、動的計算グラフ用のTensorflow Fold、pipelinesでのデータ入力に対応したTensorflow Transform、DeepMindの高レベルSonnetライブラリなど、いくつかのTensorflow系列のライブラリがリリースされました。 Tensorflowチームはまた、PyTorchの動的計算グラフと同様に機能する新しいeager実行モードを発表しました。
GoogleやFacebookに加えて、他の多くの企業が機械学習フレームワークに参加しました。
・AppleはCoreMLというモバイル・マシンの学習ライブラリを発表しました。
・UberのチームがPyro(Deep Probabilistic Programming Language)をリリースしました。
・Amazonは、MXNetで利用可能な高レベルのAPIであるGluonを発表しました。
・Uberは、内部の機械学習プラットフォームであるMichelangeloに関する詳細を公開しました。
フレームワーク全体の数が手に負えないほど増えているので、FacebookとMicrosoftは、フレームワーク全体でディープ・ラーニング・モデルを共有するためにONNXというオープンフォーマットを発表しました。 たとえば、モデルを1つのフレームワークでトレーニングしてから、別のフレームワークでプロダクションで提供することができます。
汎用のディープ・ラーニング・フレームワークに加えて、次のような強化学習フレームワークが多数リリースされました。
・OpenAI Roboschoolは、ロボットシミュレーション用のオープンソースソフトウェアです。
・OpenAI Baselinesは、強化学習アルゴリズムの高品質実装のセットです。
・Tensorflow Agentsには、Tensorflowを使用して強化学習エージェントをトレーニングするための最適化されたインフラストラクチャが含まれています。
・Unity ML Agentsは、研究者や開発者がUnity Editorを使用してゲームやシミュレーションを作成し、強化学習を使用してそれらを訓練することを可能にします。
・Nervana Coachは、最先端の強化学習アルゴリズムの実験を可能にします。
・ゲーム研究のためのFacebook's ELFというプラットフォーム。
・DeepMind Pycolabは、カスタマイズ可能なgridworldのゲームエンジンです。
・Geek.ai MAgentは、多数のエージェントの強化学習のための研究プラットフォームです。
ディープ・ラーニングをより使いやすくするという目標を達成するため、Googleのdeeplearn.jsやMIL WebDNNの実行フレームワークなど、Web用のフレームワークもいくつか用意されています。 しかし、少なくとも1つの非常に一般的なフレームワークがなくなり、それはTheanoでした。 Theanoのメーリングリストの発表で、開発者は1.0が最後のリリースになると決めました。
機械学習を学習する教材の充実
ディープ・ラーニングと強化学習が普及するにつれて、2017年にオンラインでの講義、ブートキャンプ、イベントが記録され、公開されました。以下は私のお気に入りです。
・OpenAIとUCバークレーが共催したDeep RL Bootcampでは、強化学習の基礎と最先端の研究に関する講義が行われました。*4
・スタンフォード大学の畳み込みニューラルネットワークの画像認識コース(2017年春)。*5コースのウェブサイトもチェックしてください。*6
・スタンフォード大学の自然言語処理のディープ・ラーニングコース(2017年冬)。*7コースのウェブサイトもチェックしてください。*8
・スタンフォード大学の「ディープ・ラーニングの理論」コース。*9
・ディープ・ラーニングの専門的分野に関する新しいCoursera*10*11。
・モントリオールのディープ・ラーニングと強化学習のサマースクール。*12
・UCバークレーのディープ・ラーニングと強化学習のコース(2017年秋)。*13
・Tensorflow Dev Summitは、Deep Learningの基礎と関連するTensorflow APIに関する講演を行いました。*14
いくつかの学術会議は、オンラインでの会議の打ち合わせの新しい伝統を続けました。 最先端の研究に追いつく場合は、NIPS 2017、ICLR 2017、またはEMNLP 2017の録音の一部を見ることができます。
また、研究者たちは、arXiv(無料の論文データソース)に簡単にアクセス可能なチュートリアルと研究論文を公開し始めました。 ここには今年の私のお気に入りがいくつかあります。
アプリケーション:AI&医学
2017年には、「医療問題が解決され、人間の専門家を打ち負かす」と言った旨のディープ・ラーニング技術について多くの大げさな言説が見られました。 その多くはハイプ(誇大宣伝)があり、真のブレークスルーを理解することは、医学的背景を持たない人にとってはとても困難だと思われます。 包括的なレビューするためには、Luke Oakden-Raynerの「人間医師の終わり」というブログ記事をお勧めします。 ここでは、いくつかの開発について簡単に説明します。
今年のトップニュースの中には、スタンフォードのチームが、皮膚がんの特定にディープラーニングアルゴリズムを適用し、皮膚科医と同様の精度であったとする成果に関する詳細を発表しました(Nature記事はこちら)。 スタンフォード大学の別のチームは、単極誘導心電図の情報から不整脈を心臓病専門医よりも正確に診断できるモデルを開発しました。

しかしながら、今年の成果も失敗と無縁ではありませんでした。Deep Mind社とNHS(イギリスの国民保険サービス)との契約は、「使えない」過ちに満ちていました。また、アメリカ国立衛生研究所は胸部X線データセットを科学コミュニティにリリースしましたが、より詳細な検証により、診断AIモデルのトレーニングにはあまり適していないことが判明しました。
アプリケーション:芸術とGANs
今年から多くの牽引力を獲得し始めた別のアプリケーションは、画像、音楽、スケッチ、ビデオの生成モデルです。 NIPS 2017カンファレンスでは、今年初めて創造性とデザインのための機械学習のワークショップが行われました。
最も人気のあるアプリケーションの中には、GoogleのQuick, Draw!があります。GoldDrawは、ニューラルネットワークを使ってあなたのdoodles(いたずら書き、落書き)を認識します。リリースされたデータセットを使用すると、描画を完成させるために機械に教えることさえできます。*15
今年はGenerative Adversarial Networks(GANs)が大きな進歩を遂げました。 CycleGAN、DiscoGAN、StarGANなどの新モデルでは、顔を生成するなどの面白い結果が得られました。 GANは伝統的に現実的な高解像度画像を生成するのに困難を抱えていましたが、pix2pixHDからの印象的な結果*16は、我々がこれらを解決するために進んでいることを示しています。 GANsは新時代の絵筆になっていくのでしょうか?
アプリケーション:自動運転車
自動運転市場のトップカンパニーは、自動車共有アプリケーションを提供するUber and Lyft、Alphabet's Waymo、Teslaでしょう。 Uberは、ソフトウェアエラーにより自動運転車がサンフランシスコでいくつかの赤色のライトを見逃していたため、以前報告されていたような人的ミスではなく、いくつかの挫折で1年を始めました。その後、Uberは社内で使用されているカー・ビジュアライゼーション・プラットフォームに関する詳細を共有しました。 12月、Uberの自動運転車プログラムは200万マイルに達しました。
その間、Waymoの自動運転技術は4月に初めて人間を実機に搭乗させ、その後アリゾナ州フェニックスにて人間の操縦者を完全に目的地に連れて行きました。また、Waymoはテストとシミュレーション技術についての詳細も発表しました。

Lyftはハードドライブとソフトウェアの自律的な運転を構築していると発表しました。ボストンにて、最初の操縦者を搭乗させる計画が現在進行中です。Teslaの自動運転はアップデートの大部分を見せていないなか、Appleが新規参入しました。ティム・クック氏は、Apple社は自家用車向けのソフトウェア開発に取り組んでおり、Appleの研究者はarXivにマッピング関連の論文を発表しました。
アプリケーション:その他のイケてるプロジェクト
今年は数多くの興味深いプロジェクトやデモが公開されているので、ここではそれらのすべてを言及することは不可能です。しかし、中でも目立ったものをご紹介します:
・Background removal with Deep Learning
・Creating Anime characters with Deep Learning
・Colorizing B&W Photos with Neural Networks
・Mario Kart (SNES) played by a neural network
・A Real-time Mario Kart 64 AI
・Spotting Forgeries using Deep Learning
・Edges to Cats
さらに研究面では、以下のようなものがありました。
・The Unsupervised Sentiment Neuron - Amazonのレビューのテキストの次の文字を予測するためだけに訓練されているにもかかわらず、感情の優れた表現を学ぶシステム。
・Learning to Communicate - エージェントが自らの言語を開発する研究。
・The Case for Learning Index Structures – Using neural nets to outperform cache-optimized B-Trees by up to 70% in speed while saving an order-of-magnitude in memory over several real-world data set.
・Attention is All You Need
・Mask R-CNN – A general framework for object instance segmentation
・Deep Image Prior for denoising, superresolution, and inpainting
オープンなデータセット
教師あり学習に使用されるニューラルネットワークは、データが不足していることが知られています。そのため、オープンなデータセットは研究コミュニティにとって非常に重要な貢献です。今年はいくつかのデータセットがあります:
・Youtube Bounding Boxes
・Google QuickDraw Data
・DeepMind Open Source Datasets
・Google Speech Commands Dataset
・Atomic Visual Actions
・Several updates to the Open Images data set
・Nsynth dataset of annotated musical notes
・Quora Question Pairs
ディープラーニングの再現性に関する話題
年間を通じて、学術論文の結果の再現性に関する懸念を提起する研究者もいます。ディープ・ラーニング・モデルは、膨大な数のハイパーパラメータに依存することが多く、最適な結果を達成するために最適化する必要があります。この最適化は非常に高価になる可能性があり、GoogleやFacebookなどの企業だけがそれを使用するような余裕があります。研究者は、必ずしもコードを公開しているわけではなく、完成した論文に重要な細部を入れることを忘れたり、わずかに異なる評価手順を使用したり、同じ分割上のハイパーパラメータを繰り返し最適化することによってデータセットにオーバーフィッティングが起こっていたりといったことも考えれらます。これらにより、再現性が大きな問題になります。
[1709.06560] Deep Reinforcement Learning that Mattersによれば、同じアルゴリズムでも、コードベースが異なれば、高い分散を伴って大きく異なる結果に発散されていくことが示されました。
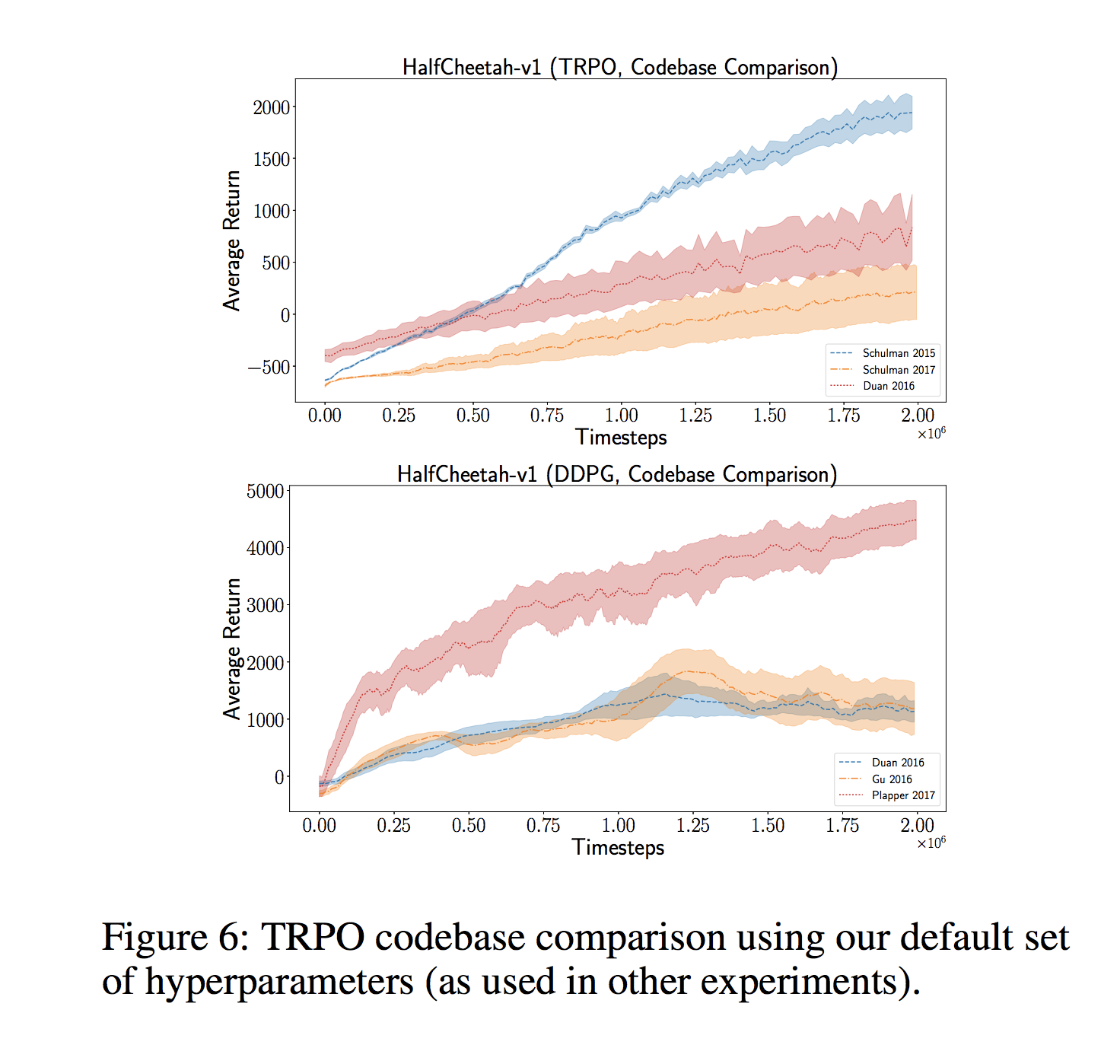
[1711.10337] Are GANs Created Equal? A Large-Scale Studyによれば、高級なハイパーパラメータ探索により適切にチューニングされたGANが、優れていると主張されていたより洗練されたアプローチに打ち勝つことができることが示されました。同様に、[1707.05589] On the State of the Art of Evaluation in Neural Language Modelsによると、単純なLSTMアーキテクチャーが適切にチューニングされると、より新しいモデルよりも優れていることが示されました。
NIPS(機械学習のトップカンファレンス)内のトークでは、Ali Rahimiが最近のディープラーニングのアプローチを錬金術と比較し、より厳密な実験デザインを求めました。このことは、多くの研究者に共感されましたが、Yann LeCunはそれを侮辱として受け取り、すぐに翌日に自身のFacebookにて反論しました。
カナダと中国の人工知能事情
米国の移民政策が厳しくなるにつれて、企業がカナダを主要な目的地として海外にもオフィスを開設するようになってきているようです。Googleはトロントに新しいオフィスを開設し、DeepMindはカナダのエドモントンに新しいオフィスを開設し、FacebookのAI Researchはモントリオールにも拡大しています。
もう一つの多くの注目を集めている目的地は中国です。多くの資本、大規模な人材のプール、政府のデータがすぐに入手できるため、AIの開発や生産展開の面で米国と対峙しています。 Googleもまた、すぐに北京で新しいラボを開くと発表しました。
ハードウェアの戦争:Nvidia、Intel、Google、Tesla
現代のディープ・ラーニング技術は、最先端のモデルを訓練するために高価なGPUを必要とすることはよく知られています。これまでのところ、NVIDIAは大きな勝者です。今年は、Titan Vという新しいフラッグシップモデルを発表しました(ちなみに、それは金ピカの製品です)。
しかし、競争は激化しています。Googleのテンソル・プロセシング・ユニット(TPU)は現在クラウドプラットフォーム上で利用可能になっており、IntelのNervanaは新しいチップセットを発表し、テスラでさえ独自のAIハードウェアで動いていると発表しています。また、ビットコインのマイニングを専門とし、この人工知能のためのGPU界隈に目をつけているするハードウェアメーカーがいる中国からも新たな競争が起こる可能性があります。
ハイプ(誇大宣伝)と失敗
ハイプには大きな責任があります。主流メディアは、実際に研究室や制作システムで起こったことについて、まったく正確に報道しているとは言えないでしょう。IBM Watsonは、過剰なマーケティングによる宣伝のイメージ・キャラクターであり、その期待に応える結果を提供することができませんでした。今年、誰もがIBM Watsonを嫌っていましたが、それは医療面での応用が何度も失敗した後も、驚くことではありません。*17
最も大きく誇大されている「お話」はおそらく、Facebookの「研究者が自分の言語を発明したAIをシャットダウンした」というものでした。それはすでに十分なダメージを与えており、グーグルにも同様の噂話があります。もちろん、タイトルは真実からそこまで遠いものではありません。実際何が起こったかというと、研究者は良好な結果を得られない標準的な実験を止めることでした。
しかし、ハイプの罪は報道にだけあるわけではありません。研究者たちもまた、このAn Adversarial Review of “Adversarial Generation of Natural Language”やFitting to Noise or Nothing At All: Machine Learning in Markets – Zachary David's
などで読める通り、実際の実験結果を反映していないタイトルや要約を世に発表してしまったことなどがありました。
注目を浴びたヘッドハンティングなんかの話題
今年は、MOOC(オンライン講義サービス)で最も有名なCourseraの共同設立者であるAndrew Ngが、今年数回にわたって報道されました。Andrewは、3月にAIグループを率いていたBaiduを去り、新たに15億ドルの資金を調達し、製造業界に焦点を当てた新しいスタートアップlanding.aiを発表しました。他のニュースでは、Gary MarcusはUberの人工知能研究所のディレクターとして辞任したり、FacebookはSiriの自然言語理解責任者を雇い、いくつかの有力な研究者がOpenAIを離れて新しいロボット会社を設立したりしました。
この科学アカデミーが産業界に気圧されている傾向は引き続き続き、大学のラボは業界の巨人が提供する給料と競争できないと不平を言っているような状況です。
スタートアップの投資と買収
前年と同じように、AIスタートアップのエコシステムは、いくつかの注目度の高い買収によって活況を呈していました。
・Microsoft acquired deep learning startup Maluuba
・Google Cloud acquired Kaggle
・Softbank bought robot maker Boston Dynamics (which famously does not use much Machine Learning)
・Facebook bought AI assistant startup Ozlo
・Samsung acquired Fluently to build out Bixby
...そして新しい会社が大金を稼ぐ:
・Mythic raised $8.8 million to put AI on a chip
・Element AI, a platform for companies to build AI solutions, raised $102M
・Drive.ai raised $50M and added Andrew Ng to its board
・Graphcore raised $30M
・Appier raised a $33M Series C
・Prowler.io raised $13M
・Sophia Genetics raises $30 million to help doctors diagnose using AI and genomic data
最後に、新年あけましておめでとうございます!長文になりましたが、最後まで読んでいただいてありがとうございます :)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
以上になります。誤訳等あったらコメントとかで教えてください、というか僕よりちゃんと詳しい人の解説を切に望みます・・・(笑)
2018年はどんなアーキテクチャやニュースが出てきて、私たちをワクワクさせてくれるのでしょうか。引き続き、目が離せませんね。
記事内の文章について、訳しているとき全てリンクなどを読めたわけではないので、言及されている内容について理解できたら、随時読みやすいように更新したり、注釈を追記していく予定なので、よろしくお願いします。
*1:Googleが開発した音声生成システム、Googleの機械学習式音声生成システムWaveNetが、Google Assistantに導入される | TechCrunch Japanなど参照。
*2:機械翻訳、RNNなどにおけるアーキテクチャの一つ、Deep Learning で使われてる attention ってやつを調べてみた - 終末 A.I.など参照。
*4:Deep RL Bootcamp - Lectures
*5:Lecture Collection | Convolutional Neural Networks for Visual Recognition (Spring 2017) - YouTube
*6:Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
*7:Lecture Collection | Natural Language Processing with Deep Learning (Winter 2017) - YouTube
*8:CS224n: Natural Language Processing with Deep Learning
*9:Theories of Deep Learning (STATS 385) by stats385
*11:コーセラは、スタンフォード大学コンピュータサイエンス教授Andrew NgとDaphne Kollerによって創立された教育技術の営利団体である。世界中の多くの大学と協力し、それらの大学のコースのいくつかを無償でオンライン上に提供している。(wikipediaより)
*12:Deep Learning (DLSS) and Reinforcement Learning (RLSS) Summer School, Montreal 2017 - VideoLectures - VideoLectures.NET
*13:CS 294 Deep Reinforcement Learning, Fall 2017
*14:TensorFlow Dev Summit 2017 - YouTube
*15:ここの文、よくわからなかった。リンクを読むと、人間が機械に教えるというより、機械がそれらしい線を提示してくるサービスのことを指しているのでは?
*16:pix2pixHDのリンク(画像あり)→High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
*17:ここもよくわからない・・・。あとでリンク先を読んで追記編集します